Eval-Driven Development
Eval-Driven Development (EDD) is a systematic approach to improving AI assistant outputs through iterative evaluation and refinement. In TextLayer Core, EDD provides a structured framework for measuring, tracking, and enhancing the performance of your AI applications.What is Eval-Driven Development?
Eval-Driven Development is a methodology inspired by Test-Driven Development (TDD) but tailored for AI systems. While traditional software development has well-established testing methodologies, AI systems present unique challenges due to their probabilistic nature and the subjective quality of their outputs. The core principle of EDD is to:- Establish evaluation criteria for your AI application’s outputs
- Create test datasets with representative examples
- Measure performance against these datasets
- Iterate on improvements based on evaluation results
- Track performance over time to ensure consistent progress
Why Use Eval-Driven Development?
AI systems often suffer from challenges that are difficult to detect through traditional testing methods:- Regression: Changes to prompts or models can cause unexpected performance drops in seemingly unrelated areas
- Hallucination: Models may generate plausible-sounding but factually incorrect information
- Consistency: Performance may vary across different input types or edge cases
- Alignment: Ensuring outputs align with human preferences and organizational values
- Objective metrics to track performance over time
- Reproducible evaluations that can be run automatically
- Early detection of regressions or unexpected behaviors
- Documentation of improvement processes for regulatory compliance
- Confidence in deploying AI systems to production
Implementation in TextLayer Core
TextLayer Core provides built-in support for Eval-Driven Development through integration with Langfuse, enabling automated testing and evaluation of your AI applications.Prerequisites
Before implementing EDD with TextLayer Core, you’ll need:- A TextLayer Core installation (see Installation Guide)
- Access to a Langfuse account for evaluation management
- Langfuse API credentials configured in your environment
Setting Up Evaluation Infrastructure
- Environment Setup
- Creating Datasets
- Setting Up Evaluators
First, configure your environment with the necessary Langfuse credentials:This enables TextLayer Core to communicate with Langfuse for evaluation tracking.
Running Evaluations
TextLayer Core provides a CLI command for running evaluations against your test datasets:- Retrieves the specified datasets from Langfuse
- Processes each test case through your application
- Logs the responses back to Langfuse for evaluation
- Associates runs with version tags for tracking progress
Analyzing Results
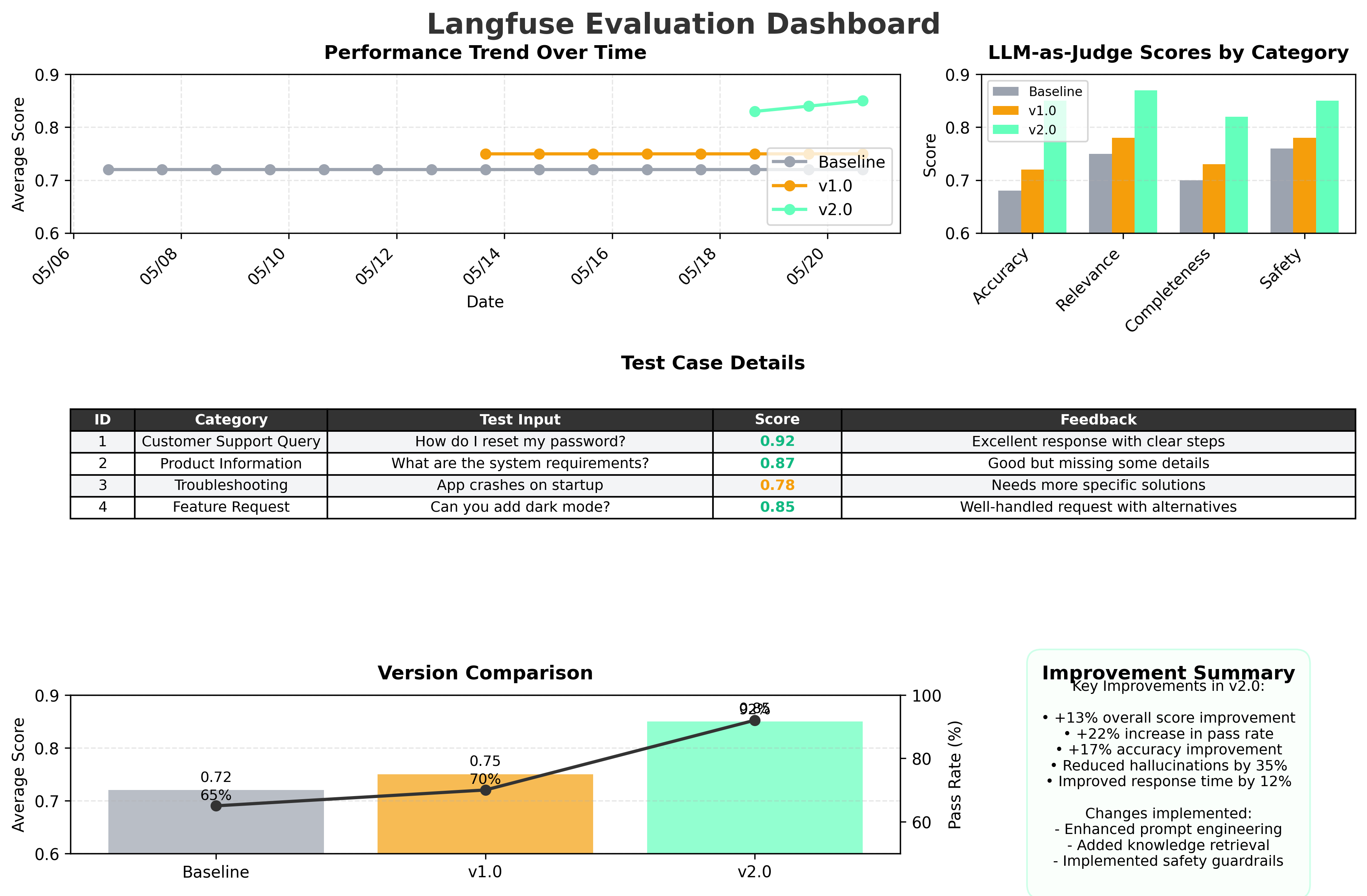
After running evaluations, analyze the results in Langfuse:- Navigate to Datasets in your Langfuse dashboard
- Select the dataset you ran tests on
- View the evaluation results, including:
- LLM-as-judge scores
- Performance trends over time
- Detailed feedback on individual test cases
- Filter by version tags to compare different iterations
The EDD Workflow
Implementing a robust EDD workflow involves several key steps:1. Identify Key Capabilities
Begin by identifying the core capabilities your AI application needs to support:- What tasks should your assistant perform?
- What knowledge domains should it cover?
- What failure modes or edge cases are critical to avoid?
2. Create Representative Datasets
For each capability, create datasets containing:- Typical examples representing common use cases
- Edge cases that test the boundaries of the capability
- Negative examples designed to trigger potential failure modes
- Golden examples that you want your system to handle perfectly
3. Define Evaluation Criteria
Establish clear criteria for what constitutes good performance:- Accuracy: Does the response contain factually correct information?
- Relevance: Does the response address the user’s query?
- Safety: Does the response avoid harmful or inappropriate content?
- Completeness: Does the response provide all necessary information?
- Efficiency: Is the response concise and to the point?
4. Establish Baselines
Run initial evaluations to establish baseline performance:5. Implement Improvements
Based on evaluation results, implement targeted improvements:- Adjust prompts to address specific issues
- Add new tools or retrievals for knowledge gaps
- Implement guardrails for safety issues
- Update model parameters for better performance
6. Measure and Iterate
After implementing changes, run evaluations again:- Targeted capabilities have improved
- Other capabilities haven’t regressed
- Overall performance is trending positively
Best Practices
Continuous Integration
Integrate evaluations into your CI/CD pipeline:Version Control for Datasets
Treat your evaluation datasets as code:- Store dataset definitions in version control
- Review changes to datasets like code changes
- Document the purpose and expected behavior of each dataset
- Update datasets as your application requirements evolve
Holistic Evaluation
Don’t rely solely on automated metrics:- Combine automated LLM-as-judge evaluations with human review
- Include both quantitative metrics and qualitative assessments
- Evaluate across multiple dimensions (accuracy, safety, user experience)
- Consider using A/B testing with real users for critical improvements
Documentation
Maintain thorough documentation of your EDD process:- Track changes to prompts, models, and configurations
- Document the rationale behind each improvement
- Keep a changelog of performance improvements
- Record decision-making processes for future reference